1. 개요
문서 객체 모델(DOM, Document Object Model)은 XML이나 HTML 문서에 접근하기 위한 기법으로 일종의 인터페이스에 해당한다.
DOM은 W3C의 표준 객체 모델이고 html의 경우 다음과 같은 계층 구조로 표현된다.

JavaScript에서는 HTML의 연결된 데이터를 가져올때 주로 사용하지만 자바스크립트 외에 XML이나 JSON에서도 사용하는 기법이다.
2. DOM의 기본 용어 정의
| 종류 | 내용 |
| Element | 요소, 문서를 구성하고 있는 단위, HTML에서는 태그가 여기에 해당한다. |
| node | 컴퓨터가 마크업 데이터를 해석하기 위해 잘라둔 조각이다. 쉽게 말해 컴퓨터가 데이터를 해석하기위해 지정한 식별키와 데이터의 조합을 말한다. (식별키는 데이터를 분류하는데 필요) |
| nodeName | 해당 노드가 가지고 있는 이름, HTML 데이터에서는 태그이름에 해당한다. |
| nodeType | 하단에 자세히 기재* (1~11까지 타입이 존재한다.) |
| nodeValue | 해당 노드의 값을 가져오는 기능, 태그의 값은 별도의 #text노드에 보관되어 있다. |
3. nodeType
노드 타입은 1번부터 11번까지 총 11개의 종류가 있다.
각 타입에 따라 할당된 번호가 다르다 . 노트타입은 노드가 가진 값 혹은 정보를 참고하여 프로그래밍의 방향을 설정하는데 도움이 된다.
| 번호 | 내용 |
| 1 | Element 노드인 경우, HTML에서는 태그 * |
| 2 | Element의 attribute(속성) 노드인 경우 * |
| 3 | #Text 노드인 경우 *** |
| 4 | CDATA, charcater data, 미리 문자를 지정하여 사용하는 경우, SQL등에서 자주 사용 |
| 5 | EntityReference, 참조 개체 |
| 6 | Entity 개체(object 객체와는 다른 개념) |
| 7 | XML 구조정의 데이터 |
| 8 | 주석 <!-- --> |
| 9 | #document 노드의 경우 |
| 10 | 선언구 <!DOCTYPE html> |
| 11 | document의 파편 |
4. DOM을 이용한 데이터 추출
DOM을 이용하여 데이터를 추출하려면 추출하려는 데이터를 특정할 수 있어야한다.
태그이름, 아이디, 클래스, Node의 name, CSS 선택자, 객체 집합등 다양한 방법을 사용할 수 있다.
1) HTML 태그 이름(tag name)을 이용한 선택: getElementsByTagName()
var selectedItem = document.getElementsByTagName("li"); // 모든 <li> 요소를 선택함.
for (var i = 0; i < selectedItem.length; i++) {
selectedItem.item(i).style.color = "red"; // 선택된 모든 요소의 텍스트 색상을 변경함.
}
2) 아이디(id)를 이용한 선택: getElementById()
var selectedItem = document.getElementById("even"); // 아이디가 "even"인 요소를 선택함.
selectedItem.style.color = "red"; // 선택된 요소의 텍스트 색상을 변경함.
3) 클래스(class)를 이용한 선택: getElementsByClassName()
var selectedItem = document.getElementsByClassName("odd"); // 클래스가 "odd"인 모든 요소를 선택함.
for (var i = 0; i < selectedItem.length; i++) {
selectedItem.item(i).style.color = "red"; // 선택된 모든 요소의 텍스트 색상을 변경함.
}
4) name 속성을 이용한 선택: getElementByName()
var selectedItem = document.getElementsByName("first"); // name 속성값이 "first"인 모든 요소를 선택함.
for (var i = 0; i < selectedItem.length; i++) {
selectedItem.item(i).style.color = "red"; // 선택된 모든 요소의 텍스트 색상을 변경함.
}
5) CSS 선택자(selector)를 이용한 선택: querySelectorAll()
var selectedItem = document.querySelectorAll("li.odd"); // 클래스가 "odd"인 요소 중에서 <li> 요소만을 선택함.
for (var i = 0; i < selectedItem.length; i++) {
selectedItem.item(i).style.color = "red"; // 선택된 모든 요소의 텍스트 색상을 변경함.
}
6) HTML 객체 집합(object collection)을 이용한 선택
var title = document.title; // <title> 요소를 선택함.
document.write(title);
5. DOM을 이용한 데이터 변경
DOM을 이용한 요소의 내용 변경에는 일반적으로 innerHTML을 사용하거나 속성의 값을 변경하는 방식으로 접근한다.
1) innerHTML 사용
var str = document.getElementById("text");
str.innerHTML = "이 문장으로 바뀌었습니다!";
2) Tag의 속성값 변경
var link = document.getElementById("link"); // 아이디가 "link"인 요소를 선택함.
link.href = "/javascript/intro"; // 해당 요소의 href 속성값을 변경함.
link.innerHTML = "자바스크립트 수업 바로 가기!"; // 해당 요소의 내용을 변경함.
3) Tag의 스타일 변경
var str = document.getElementById("text"); // 아이디가 "str"인 요소를 선택함.
function changeRedColor() { str.style.color = "red"; } // 해당 요소의 글자색을 빨간색으로 변경함.
function changeBlackColor() { str.style.color = "black"; } // 해당 요소의 글자색을 검정색으로 변경함.
6. Node의 구조와 이해

마크업된 언어인 HTML에서 데이터의 포함관계는 태그의 닫히고 열림으로 파악된다.
컴퓨터는 이 태그를 해석하는 과정에서 각 태그를 식별할 수 있는 key가 필요하다.
이러한 key와 데이터가 합쳐진 구조를 node라고 한다. node는 다양한 종류가 있으며, 문서 객체 모델인 HTML에서는 문서 노드가 요소 노드를 다수 포함하고 있고, 이 요소노드는 속성 노드와 텍스트 노드를 포함하고 있다.
HTML은 마크업된 태그의 집합이고, 이 집합을 이루는 태그는 ‘노드’의 집합인 것이다.
노드는 앞서 배운 객체와 굉장히 유사한 모양을 가지는데, 앞서 배운 객체의 프로퍼티가 노드의 모양가 같기 때문이다.
- 프로퍼티: var Object = {name: jay, age: 30, hobby: boardgame};
- 노드: ElementNode: TagName: div - Attribute: id=”wrap”
즉, 해당 노드의 키로 노드 자체에 접근하면 안에 담긴 데이터를 조정할 수 있다는 것이다.

쉽게 말해서 노드에는 특정 데이터를 식별하기 위해 특수한 구조를 가지고 있고, 이 노드는 개발자가 지정하지 않는다면 브라우저가 자동으로 생성하고 해석한다.
이러한 구조적인 특성으로 인해 일부 데이터는 실제 데이터 값이 없음에도 ‘노드’만을 가지고 있을 수 있다.
위의 구조에서 데이터가 없음에도 생성된 text 노드가 대표적인 예이다.
이러한 노드 생성은 개발자가 컨트롤하려는 데이터를 특정하는데 방해요소가 되므로 반드시 데이터를 조작할 때 구성된 노드의 리스트를 확인하여야 한다.

이러한 노드의 구조는 각 노드가 특정 요소에 포함된 상태임을 말하며, 더 나아가 이 노드자체도 형제나 부모 요소를 가진다는 것이다.
다르게 말하면 형제 혹은 부모를 지정했던 CSS 의 선택자의 개념으로 노드 데이터를 추출하거나 선택하는게 가능하다는 말이다.

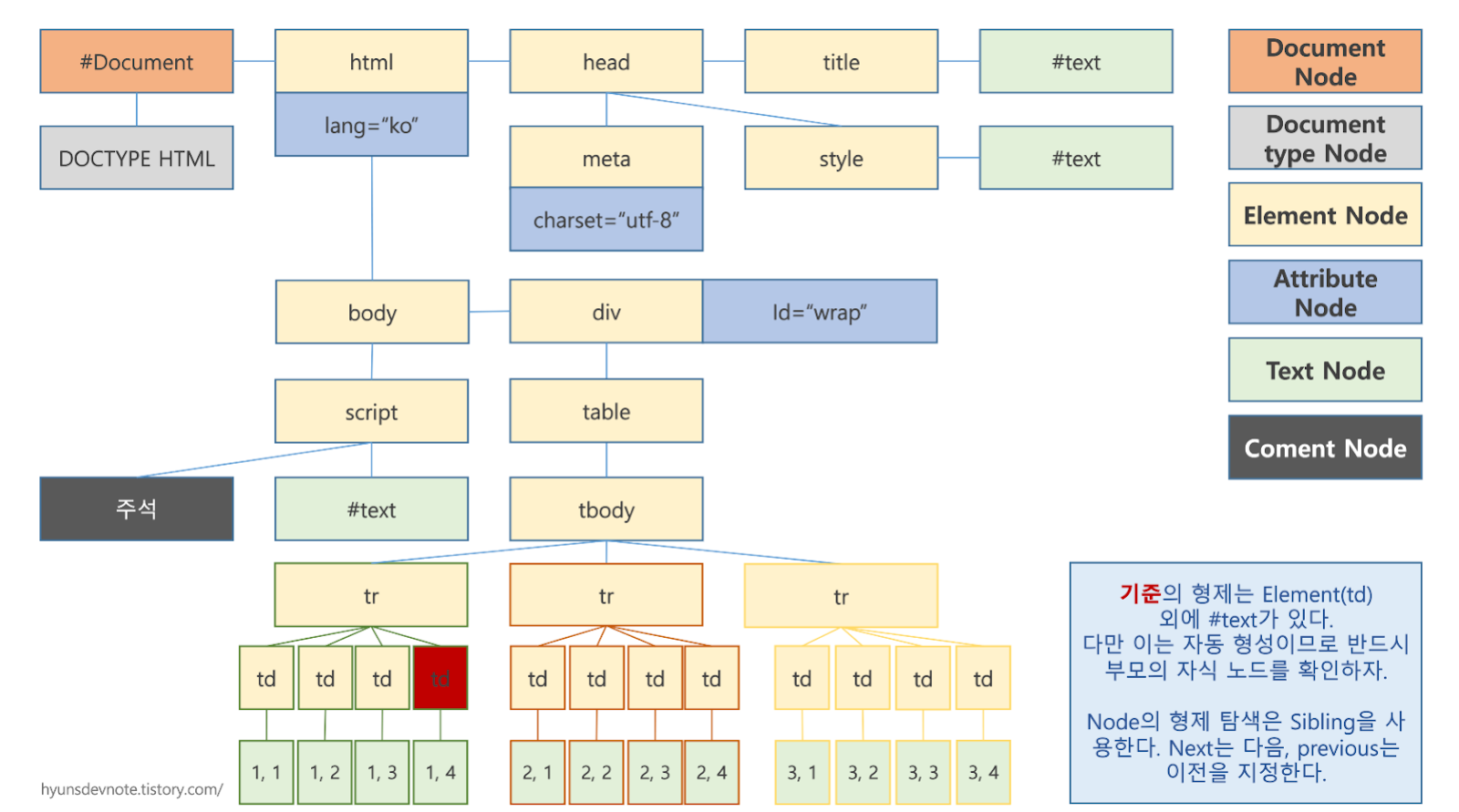
위의 그림과 같이 어떤 요소를 기준으로 하느냐에 따라 형제와 자식 노드와 관계가 변화한다.
때문에 기준으로 정한 요소에 대해서 next나 previous를 이용하여 선택하고 데이터를 조작할 필요가 있다.
7. DOM의 기본 사용법과 Node 데이터를 조작하는 방법
1) DOM의 기본 사용법
자바스크립트에서 DOM을 사용하려면 우선 지정하는 지정 데이터를 변수에 담을 필요가 있다.
변수에 담기지 않은 데이터는 휘발해버리기 때문이다.
본래 특정 요소나 데이터에 접근하기 위해 계층구조로 이루어진 데이터를 경로에 따라 지정하고 함수를 통해 데이터를 변경한다. 아래의 예시를 보자.
//예제 1)
console.log(document.getElementById ("wrap").getElementsByTagName ("p")[0]);
//예제 2)
let wrap = document.getElementById ("wrap");
let ps = wrap.getElementsByTagName ("p")[0];
console.log(ps);
가장 상단에 작성한 DOM ex1 과 3줄에 걸쳐 작성한 DOM ex2은 같은 내용이다.
코드 라인을 기준으로 한다면 분명 ex1이 더 효율적인 모양일 것이다.
하지만 만약 위의 데이터 구조에서 p태그에 대한 데이터를 추가로 수집해야한다면 어떨까?
그럴 경우, 변수로 해당 DOM을 지정한 ex2가 더욱 효율적인 코딩 방법일 것이다.
이와 같이 DOM의 기본 골자는 경로를 따라 데이터를 추출하는 것이고, 이 과정에서 적절하게 변수를 활용하는 것이 가장 이상적인 형태이다.
2) 노드를 선택하는 방법
노드 데이터는 문서 구조에서 데이터를 나타내는 각 요소로, DOM을 통해 접근이 가능하다.
노드를 다루기 위해서는 노드 타입, 노드의 리스트, 노드가 가진 값, 노드의 전후로 위치한 노드를 파악하는 등 다양한 데이터를 파악하고 조작해야 한다.
| 종류 | 내용 |
| nodeType | 노드의 타입을 확인한다. |
| childNodes | 해당 요소(노드)가 가진 자식 노드를 선택한다. |
| childNodes[i] | 해당 요소의 자식 노드 중에 i 번째 노드를 선택한다. |
| parentNode | 해당 노드의 부모 노드를 선택한다. |
| previousSibling | 해당 노드의 형제 노드중 해당 노드보다 이전 노드를 선택한다. (==부모 노드에 대해 childNode[i-1]) |
| nextSibling | 해당 노드의 형제 노드중 해당 노드보다 다음 노드를 선택한다. (==부모 노드에 대해 childNode[i+1]) |
| attributes | 해당 노드와 연결된 속성 노드를 선택한다. 주의할 것은 속성 노드는 ‘자식 노드’가 아니다. |
3) Element 혹은 Node의 속성과 내용을 조작하는 방법
① .setAttribute(“속성이름”, “속성이름에 포함되는 값”)
속성 노드는 해당하는 속성에 대한 ‘정보’가 필요하다.
때문에 속성 이름을 표시하고 , (쉼표)로 구분하여 “속성”이 가져야할 값을 작성한다.
때문에 값을 직접할당한다기 보다 객체의 포로퍼티를 새로 만드는 형태라 setAttribute를 사용한다.
② .innerHTML=” ”
“” 안에 데이터로 해당 노드가 가진 ‘값’이 변한다.
//예제 1)
let ce=document.createElement("td"); //만들어진 노드, 위치를 지정하지 않아 화면 표시X
ce.setAttribute("style","background-color:crimson; color:white;");
ce.innerHTML="Ce";
4) 노드 데이터를 생성, 삽입, 삭제, 교체, 복제하는 방법
HTML은 결국 포함관계를 가진 노드의 집합체이다.
이에따라 노드 자체를 생성하거나 삽입하는 것이 가능하다.
| 종류 | 내용 |
| document..createElement(“name”) | name인 Element를 생성한다. 즉 name이란 태그를 생성하는 것이다. Element |
| document.createTextNode("String") | 내용이 String인 텍스트 노드를 생성한다. |
| .insertBefore(“노드를 담은 변수”, 위치); | 위치 이전에 해당 노드를 삽입한다. |
| .replaceChild(“노드를 담은 변수”, 위치); | 위치에 있는 노드를 새로운 노드와 교체한다. 기존 노드는 고아노드가 된다. |
| .removeChild(“노드를 담은 변수”, 위치); | 해당 위치의 노드를 제거한다. 기존 노드는 고아노드가 된다. |
| .cloneNode(true) | 해당 노드를 복제한다. |
| .normalize() | 데이터가 없는 Node를 제거하고 기존 모양으로 복귀시킨다. |
노드를 만든 경우, 어떤 Node에도 연결된 상태가 아니므로 실질적으로는 ‘부모’가 없는 고아노드이다.
결국 HTML의 모양은 Document 노드에 포함된 Elements를 표현하는 것이기 때문에 최소한 부모로 Documents를 가져야하며, 그 안에서 브라우저 화면에 구현한다면 Body안에 위치해야한다.
이에 생성한 노드는 insertBefore(생성한 노드 이름, 위치) 를 이용해 삽입해야한다.
(insertAfter는 없다) 또한 원치않는 노드가 있거나 데이터를 조작하거나 사용자의 입력 값에 따라 노드 데이터를 삭제해야한다면 removeChild 등을 이용할 수 있다.
(remove를 통한 제거는 연결만 제거한다.) 만약 노드를 복제하고 싶다면 변수에 해당 노드에 대한 위치를 선택하고 cloneNode(true); 메소드를 사용한다.
복제한 노드는 기본적으로 고아 상태임을 기억하자. 마지막으로 데이터를 더 빠르게 연산하거나 값이 비어있는 텍스트 노드를 하나의 노드로 만들고 싶다면 normalize() 메소드를 이용한다.
해당 메소드는 DB의 정규화 과정중 NF 와 유사하다. (예시코드 DOM-A.html)
'JavaScript > 기본 이론' 카테고리의 다른 글
| Chapter 16. 이벤트 (0) | 2021.12.02 |
|---|---|
| Chapter 15. 브라우저 객체 모델 (BOM) (0) | 2021.12.01 |
| Chapter 13. 객체의 이해 (0) | 2021.11.29 |
| Chapter 12. 변수와 호이스팅 (0) | 2021.11.28 |
| Chapter 11. canvas (객체의 기본 이해) (0) | 2021.11.27 |